やりたいこと
俯瞰で見ているUSBカメラの画像を使って、自律的に動いているロボットの向きを検出する。
また、カメラ画像における指定の座標と、ロボットがなす角を算出する。
動作環境
- ターゲットボード
- JetsonNano
- OS
- Ubuntu 18.04.4 LTS
- 使用ライブラリ
- Python版 OpenCV 4.1.1
処理結果
今回実装した処理の結果は、画像で示すと以下のような感じになる。

方法
今回実装した方法は以下の通り。
- カメラ画像をHSV形式に変換
- カメラ画像のうち指定のHSV範囲に従ってマスク画像を作成
- マスク画像から輪郭を抽出し、1番面積の大きい領域のみ残したマスク画像を作成
- カメラ画像とマスク画像の共通領域を抽出
- 4.で作成した画像から黒色領域を抽出
- 5.で抽出した黒色領域のうち、1番面積の大きい領域の重心p1、2番目に面積の大きい領域の重心p2を計算
- p2からp1へのベクトルと、p1とp2の中点から指定の座標へのベクトルのなす角を計算
処理順に従って中間生成画像を並べると以下のような感じになる。
元画像

手順3.で作成したマスク画像

手順5.で抽出した黒色領域

手順6.で算出した各黒色領域の重心

処理結果
ソースコード
一部自作モジュールもimportしているのでコピペでは動きません。
呼び出し方は例えば以下のように。
処理時間や実行時のリソース使用量など
処理時間
今回の一連の処理呼び出しにどれだけ時間がかかっているか計測したところ、以下の通りだった。
elapsed_time:0.49050045013427734[sec]
elapsed_time:0.500530481338501[sec]
elapsed_time:0.49204468727111816[sec]
だいたい0.5秒ほどかかっている。このままだとリアルタイム性が求められる場合は使えない。
リソース使用量
Jetsonのモニタツールjtopの出力は以下のような感じ。
プログラム稼働中
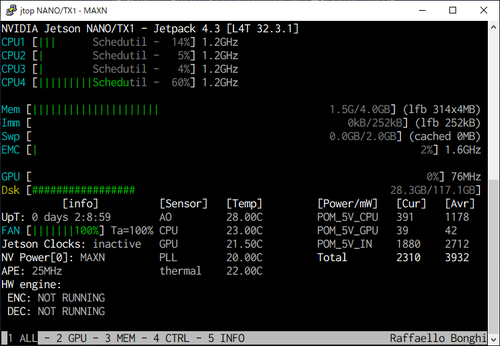
GPUが稼働していない。GPUを使うようにすれば高速化できるのだろうか(全然そこらへんは調べていない)。
なぜこの処理を実装したか
全体を俯瞰できるカメラの情報を使って、ロボットを指定位置に誘導したかった。
カメラ側がロボットに指定の位置に対する角度・距離情報を伝え、ロボット側でその情報を使って、モータ値を計算する。
設計の経緯や苦労したところなど
目印をどう設計するか
向き検出のための目印をどう設計するかが、検出精度や処理速度に最も影響を与える部分だと思う。
今回は黄色の画用紙の上に、面積の異なる黒色の画用紙を2つ(前方に面積が大きいもの、後方に面積の小さいもの)つけて目印にした。
単純だが、思っていたより認識出来ていたと思う。しっかりしたベンチマークはとっていないが。
最初はQRコードの活用を考えていた。OpenCVにはQRコード認識処理が実装されており、向きも検出出来そうだったので。今後複数台ロボットを同時に動かすことを考えても、QRコードだったら文字列情報を付加できるので、各ロボットの識別に使えそうとも思っていた。
ただ、ある程度QRコードが大きく写っていないと認識できなかった。今回はカメラと認識対象ロボットの距離が遠い時でも認識できるようにしたかったので、QRコード案はやめた。
画像処理の実装はそこまで苦労しなかった
OpenCVはネットに情報がたくさん落ちているので、処理実装部分はそこまで苦労しなかった。今回実装した処理はほぼネットで紹介されている実装方法をそのまま使っている。
雑記
VSCodeのRemote-SSH機能が非常に使いやすかった。
